Faster A* For Games
Faster A* For Games Gameplay Programming @ DAE
Introduction
The technique I used is mainly called Goal Bounding, it is an optimization technique for pathfinding algorithms. In theory, it can be applied to any search graph. After some digging, I stumbled upon a paper written by Steve Rabin and Nathan R. Sturtevant [1] where they explain the core fundamentals of how this works. I'm going to take it a step further and implement it into a basic pathfinding program.
Github sourceDownload Executable
Main Goal
Concept
The main goal of this project is to optimize a pathfinding algorithm at runtime by pruning (excluding) large chunks of areas from a so-called "search graph". This check can be done by checking bounding boxes for each connection from a node with the optimal route to a goal node. These bounding boxes are computed at different times but before the actual runtime. Computation time will increase relative to how large your search graph is. But never the less, the algorithm at runtime will run faster because of those exclusions.

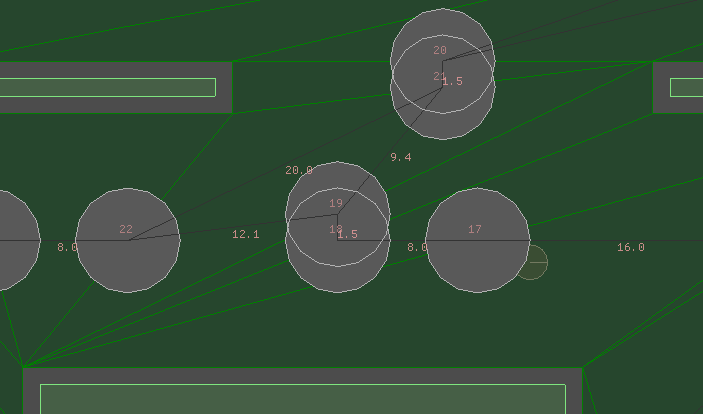
Here you can see three bounding boxes precomputed for each edge of the
black node. (Source: Faster A * with goal bounding) [1]
Optimization
Requirements
The search graph must be static, in other words, it can not change. Since that would simply mean we would have to recompute all the bounding boxes. And this can not be done at runtime.
It is important if u have a large NavMesh that these precomputations are happening before release. You will have to save the data to a file, so you can allocate the memory needed for this data on the RAM when initializing the game/program. (I recommend saving the data as pure binary)
Implementation
Computation Algorithm

The approach I took is slightly different. Since my nodes are not in the centre of a triangle/square but in the middle of each edge of a triangle containing an adjacent triangle/square.
Because of this, the interpretation of terms in my code will be
different from the terms mentioned in the source paper.
connection =
edge = d = neighbor;
current record = node = n;
This is how the enhanced Dijkstra method works:
So what information we actually need is for each node the optimal starting
connection. This information is available to us in a normal Dijkstra
algorithm, it's just not stored since we don't need it in a normal
Dijkstra algorithm. To actually step through each node during a Dijkstra
algorithm, we don't give a Goal node (goal node is the same as start
node). This gives it the effect of flood fills the whole graph. Doing
this, we will have each node checked. To save this data you need to pass
that connection's ID to its children, each time you push a new record to
the open list.
Having this information we can compute a bounding box for each connection
of a node.
Other Computation
I've stumbled upon another approach when implementing this. What if you could store for each node a container containing a container representing each node its optimal start connection.
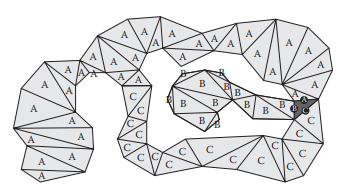
Here you can see all the nodes containing the optimal start connection from the black node. Do that for each node and you would simply have to check if your goal node's optimal start node is the same as your currentConnection in the foreach(connection of currentNode) of the while loop. Using this in my implementation you would need to link the start and goal node each to their closest node. Because the start and goal node are not present when acquiring this information.
Runtime Algorithm

When implementing this algorithm I stumbled upon some problems. The start
& end-node were not present when computing the bounding boxes.
That left me with 2 options:
1: I could find the closest valid Node and work my way up from there.
2: I could check if I'm working with a start or end node and skip the
check.
I choose to work with my second option.
Check if I can do the Bounding Box check
So it was said, you need to check if the Goal Position is in a
connection's assigned bounding box from the currentNode to actually
continue the search. That is really it, but it was tricky to actually
implement it. Since I had a dynamic Start and Goal node, which are added
at run time. Since these are only 2 nodes, I did a simple check to skip
them.
This is the check if the connection is related to the Start or a Goal node
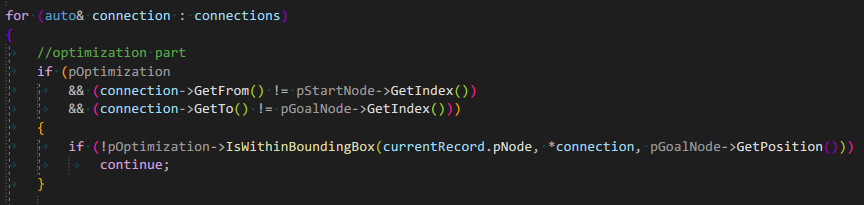
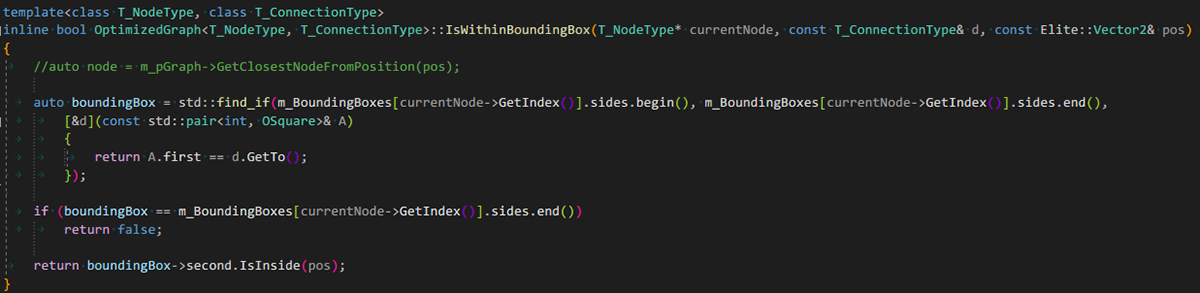
Bounding Box Check
This shows how I implemented the Bounding Box check.
1: I find if the bounding Box at the node connection exists, If it doesn't
exist there was no optimal route.
2: If it does exist, I check if the Goal(pos) is within that bounding box.
If it is, that means that connection is the optimal start connection for
that Goal node.
Conclusion
In my opinion, this can really speed up any Path Finding procedure. When
considering the constraints for this method, and implementing it right. I
really had fun implementing this optimization technique, it gave me a
bigger perspective of what you can do with pathfinding and how large the
spectrum actually is of the pathfinding branch.
If there are any questions or you want to give feedback, feel free to
contact me.
Download Executable
References
Steve Rabin and Nathan R. Sturtevant, Faster A * with Goal Bounding [1]